and it is deadly simple
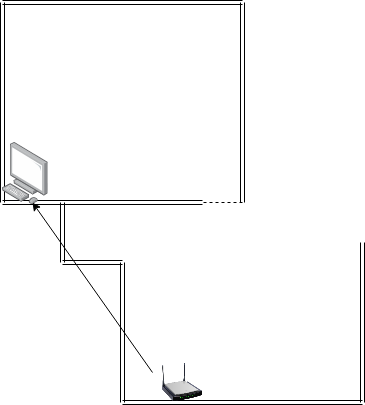
So, here is the problem. Although my apartment is just a small one and the distance between the Wifi router and my PC is also not far, they are separated by some wall layers.
and it is deadly simple
So, here is the problem. Although my apartment is just a small one and the distance between the Wifi router and my PC is also not far, they are separated by some wall layers.
Nothing special here. It’s just a blog post for summarising my algorithm learning course. Although this was already taught in the University, it’s still god to summarize here
Key-value pair abstraction.
Example
| domain name | IP address |
|---|---|
| www.cs.princeton.edu | 128.112.136.11 |
| www.princeton.edu | 128.112.128.15 |
| www.yale.edu | 130.132.143.21 |
| www.harvard.edu | 128.103.060.55 |
| www.simpsons.com | 209.052.165.60 |
Symbol Tables act as an associative array, associate one value with each key.
public class ST<Key, Value> {
void put(Key key, Value, val);
Value get(Key key);
void delete(Key key);
boolean contains(Key key);
boolean isEmpty();
int size();
Iterable<Key> keys();
}At the time of this writing, I have been working at Agency Revolution (AR) for more than 2 years, on a product focusing mostly on automation email marketing for the Insurance Agencies. I have been working on this product since it was in beta, when it could only serve only a few clients, send thousands of emails each month and handle very little amount of integration data without downtime until it can deliver millions of emails each month, store and react to terabytes of data flow every day. The dev team has been working very hard and suffering a lot of problem to cope with the increasing number of customers that the sale team brought to us. Here the summary of some techniques and strategies that we have applied in order to deliver a better user experience.
By On-demand, I mean the action of computing the required data only when it is needed.
One of the core value of our system is to deliver the right messages to the right people at the right time. Our product allows users to set up automated emails, which will be sent at a suitable time in the future. The emails are customised to each specific recipient based on their newest data at the time they receive the email, for example the current customer status, whether that customer is an active or lost customer at that time, how many policies he/she has or the total value that customer has spent until that time.
Read morePart 1 here Some Optimizations in RethinkDB - Part 1
Yes, it’s RethinkDB, a discontinued product. Again, read my introduction in the previous post. It’s not only about RethinkDB but it also the basic idea for many other database systems. This post introduces other techniques that I and the team have applied at AR to maximize the workload that RethinkDB can handle but most of them can be applied for other database systems as well.
Well, sound like a very straight forward solution, huh? More memory, better performance, sound quite obvious! Yes, the key thing is how to increase the memory without significant cost. The answer is to setup swap as the temporary space for storing RethinkDB cached data. RethinkDB, as well as other database systems, caches the query result data into memory so that it can be re-used next time the same query executes again. The problem is that swap is much slower than RAM, because we rely on the disk to store the data. However, since we are running on Google Cloud and Google Cloud offers the Local-SSDs solution, we have been exploiting this to place our swap data. Here is the Local-SSDs definition, according to Google
Read moreLocal SSDs are physically attached to the server that hosts your virtual machine instance. Local SSDs have higher throughput and lower latency than standard persistent disks or SSD persistent disks. The data that you store on a local SSD persists only until the instance is stopped or deleted.
Feature Toggle is a very popular technique that enables you to test the new feature on real production environment before releasing it to your clients. It’s also helpful when you want to enable the feature for just some beta clients or just some clients who pay for the specific features. The technique requires both backend and frontend work involved. In this post, I’m going to talk about some simple solutions that I and the team at AR have applied as well as some other useful ways that we are still discussing and may apply one day in the future.
Of course, the simplest solution is to create a specific table for storing the all the feature flags in the database. The table may looks like this
{
featureName: <string>,
released: <bool>,
enabledList: <array>, // enabled clients list
disabledList: <array> // disabled clients list
}
The above mentioned data structure may be suitable for the case your system has a lot of users. You
can simply add some admin user to the enabledList and test the new feature on production before
releasing it to your users.
If your product is to serve business clients, you can also store the enabled feature directly to the client object itself. This can save you extra queries to the database to get the feature information. If that’s the case, your Client object might look like this
{
clientId: <string>,
enabledFeatured: <array>
}
Nothing special here. It’s just a blog post for summarising my algorithm learning course. Probably this was taught in the University but I don’t remember anything, I have no idea about its definition and applications until I take this course. Part 1 here Binary Heap & Heapsort Summary - Part 1 - Binary Heap
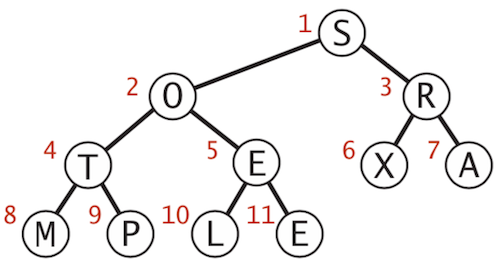
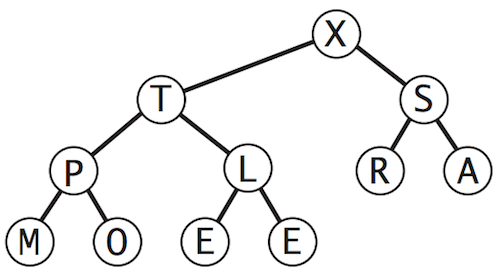
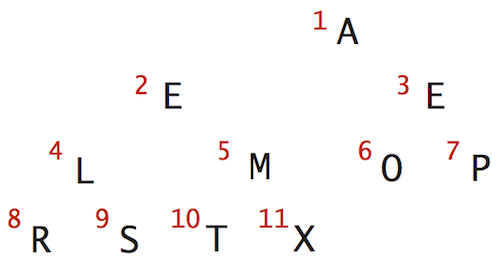
Nothing special here. It’s just a blog post for summarising my algorithm learning course. Probably this was taught in the University but I don’t remember anything, I have no idea about its definition and applications until I take this course.
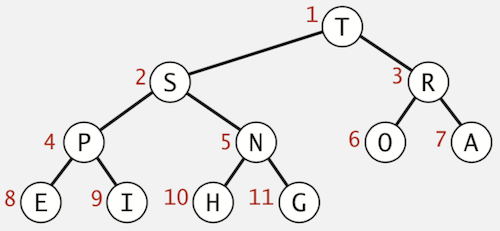
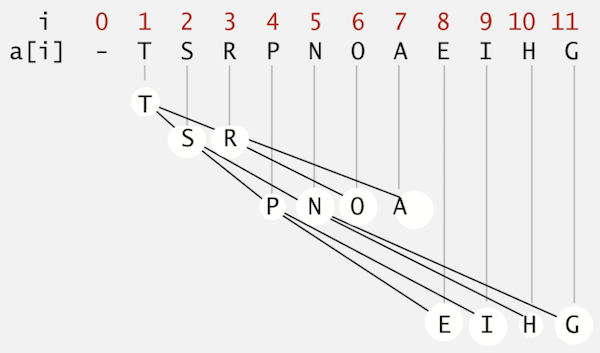
Nothing special here. It’s just a blog post for summarising my algorithm learning course. Although this was already taught in the University, I remember nothing about it because I haven’t touched it for the long time.
Partition array into 3 parts so that:
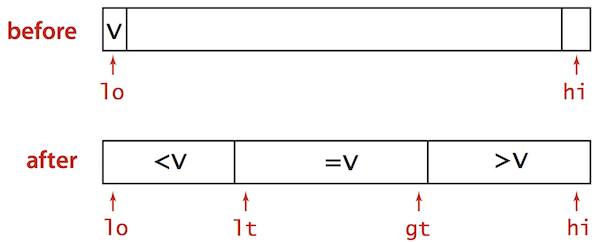
v be partitioning item a[lo]i from left to right.
(a[i] < v): exchange a[lt] with a[i]; increment both lt and i(a[i] > v): exchange a[gt] with a[i]; decrement gt(a[i] == v): increment iNothing special here. It’s just a blog post for summarising my algorithm learning course. Although this was already taught in the University, I didn’t even know that it can be used for Selection Problem
Given an array of N items, find a kth smallest item. For example, an array A =
[5, 2, 9, 4, 10, 7], the 3rd smallest item is 5, the 2nd smallest item is 4 and the smallest
item is 2
a[j] is in place.jjj, finished when j equals kNothing special here. It’s just a blog post for summarising my algorithm learning course. Although this was already taught in the University, I remember nothing about it because I haven’t touched it for the long time.
The Idea
