Part 2 Mistakes of a Software Engineer - Favor NoSQL over SQL - Part 2
Is that all problems that I have with NoSQL?
No. But I’m lazy now 😂. So I won’t talk about the problems anymore.
Choosing a Database system with a Product perspective
So, how do I choose a database system from my Product engineer view?
The answer is: It depends. (of course 😂)
The philosophies of the 2 database systems are different.
NoSQL is designed for simple operations with very high read/write throughput. It best fits if you usually read/write the whole unstructured object using very simple queries. There are some specific use cases that you can think about
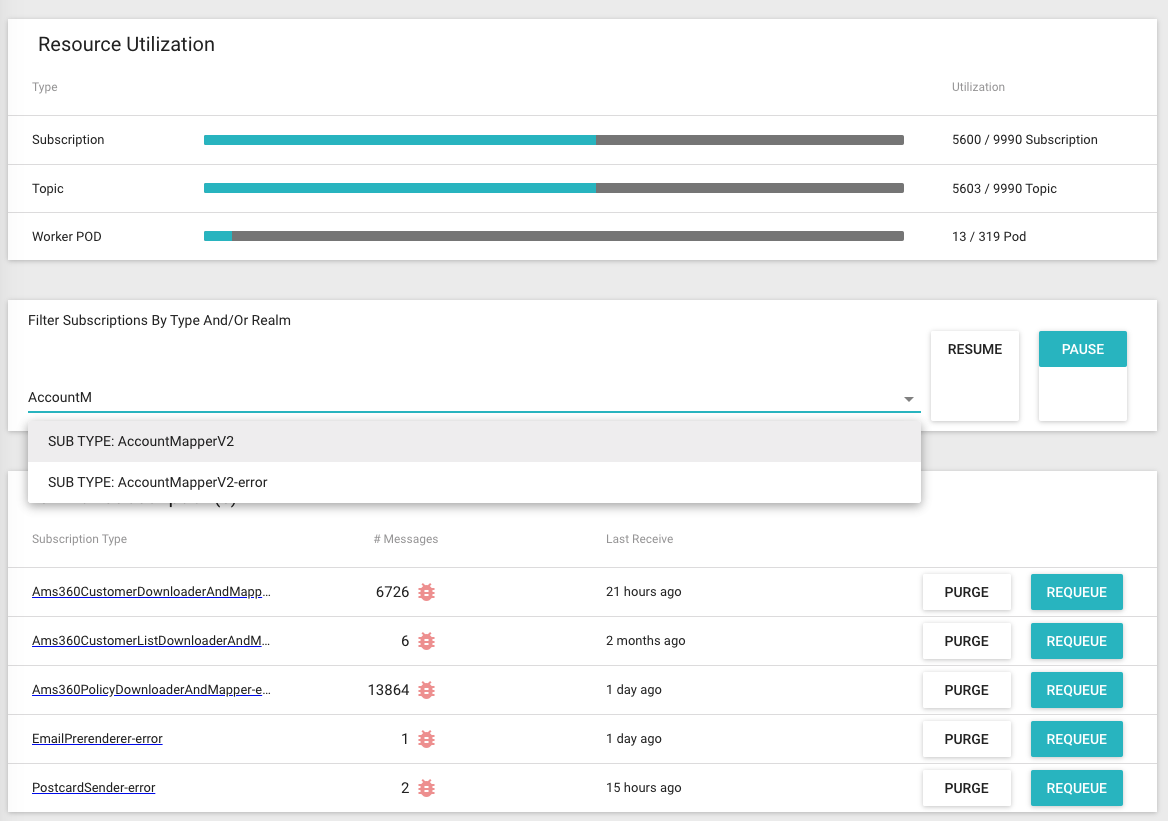
- Receive data from another system (an integration API for example): You can use a NoSQL database as a temporary storage to increase API response time and safety by deferring data processing to a later time. Read more Scaling the System at AR - Part 2 - Message Queue for Integration
- A backing service to store Message Values for a Message Queue application
- A caching database where you know exactly what you need and you can query easily by key value (but even in this case, think of other solution in SQL first, like materialized views, triggers,…).
- Others?