Part 3: Scaling the System at AR - Part 3 - Message Queue in general
Continue from my previous post, I’m going to demonstrate the internal tool that we use at AR to work with Message Queue. I will also summarize some of our experience when designing a system with Message Queue.
The Message Queue in AR system
Currently, we have over 100 different types of workers/queues. We have built a tool to manage them efficiently.
The tool allows us to quickly filter for any Subscriptions (Queues/Workers)
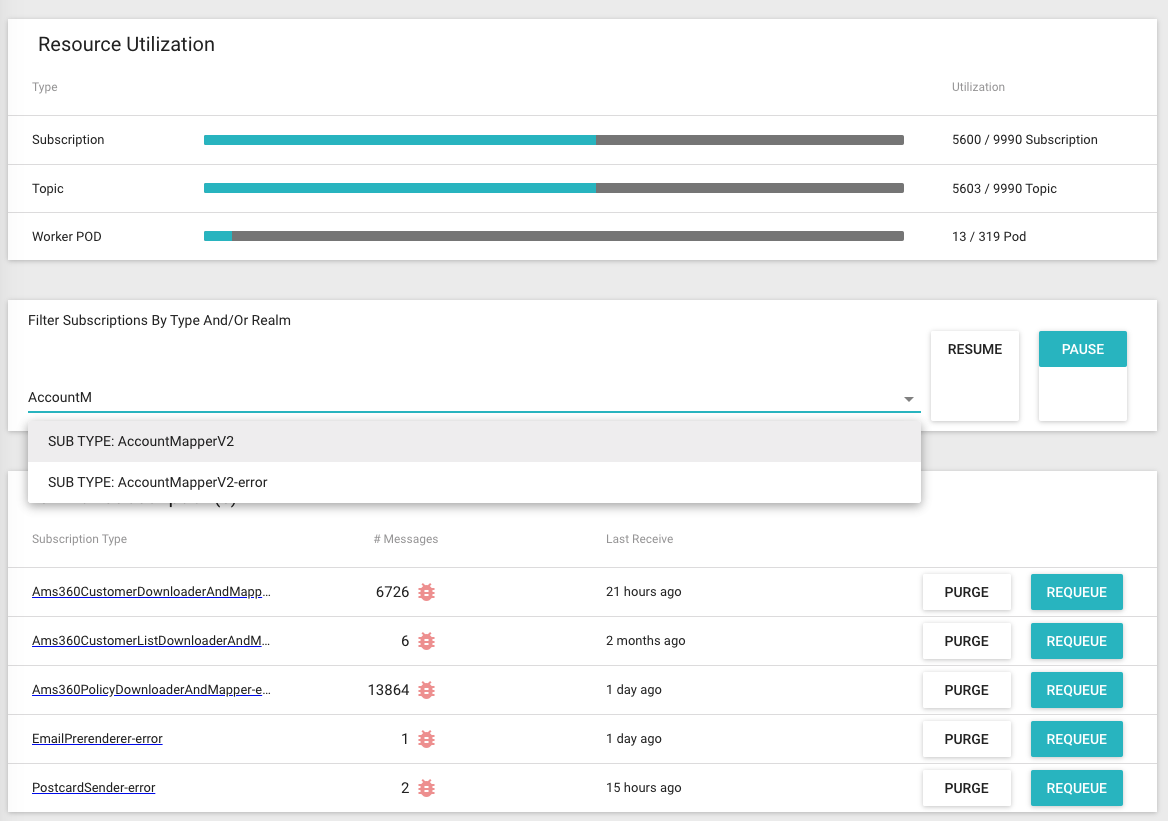
We also built a mechanism to partition some of the workers by each client (realm)
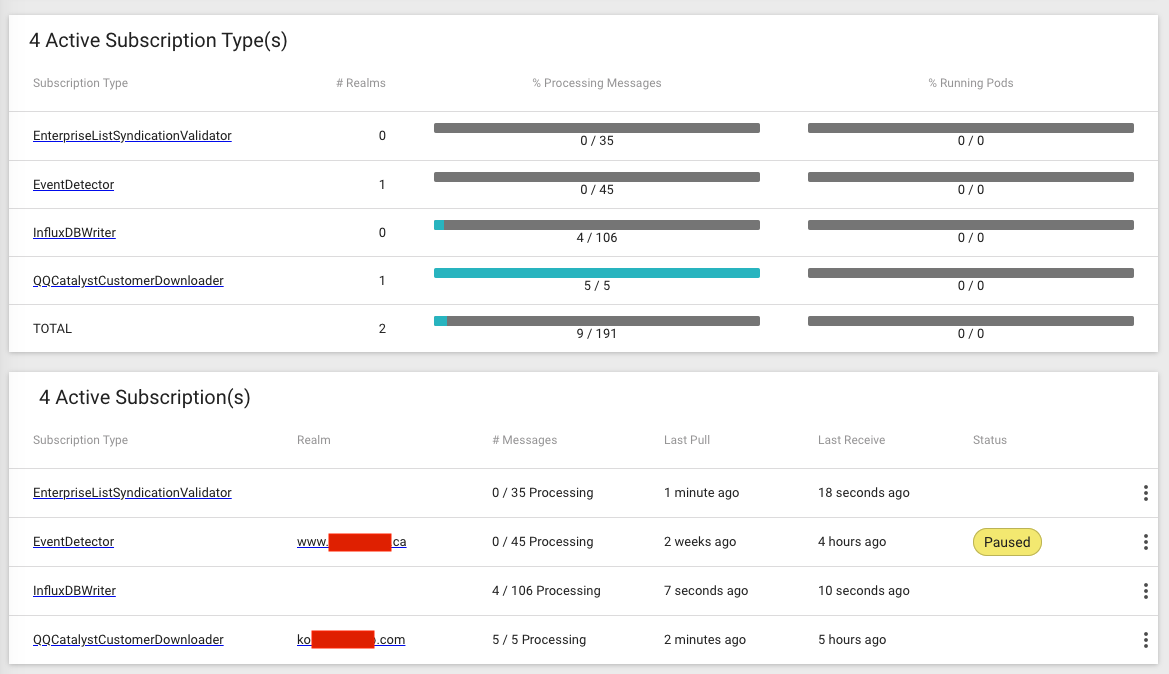
That way, we can quickly identify which client or which worker is consuming the most resources of
the system and control them easily
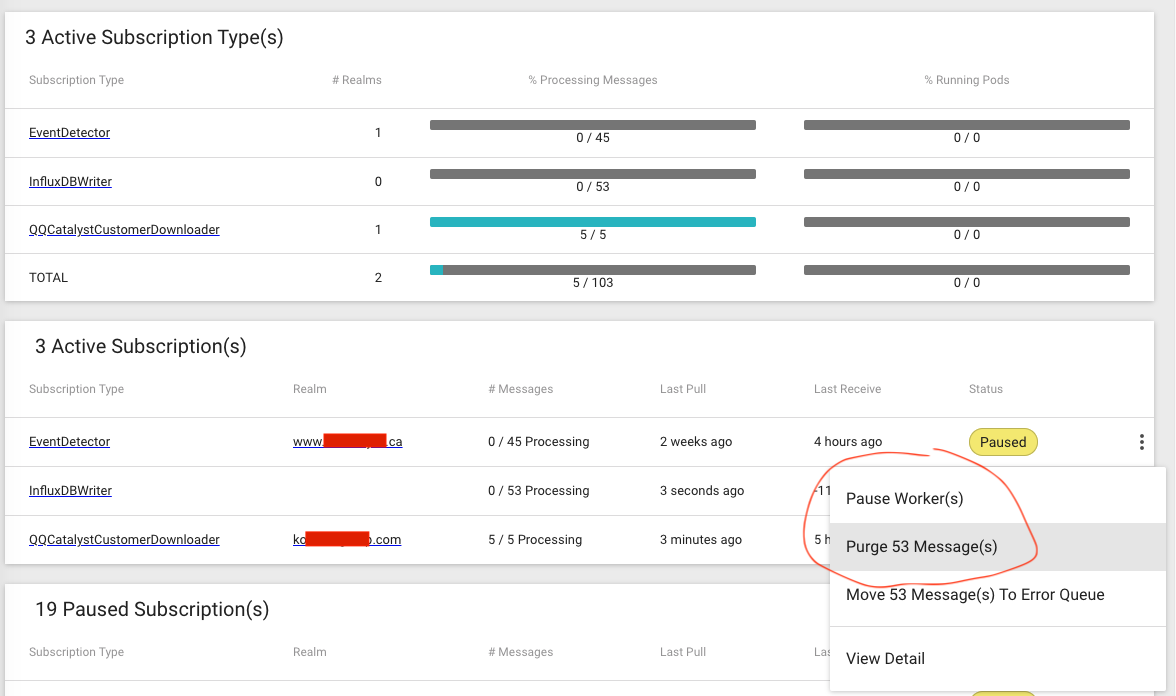
The error messages are in Error queues, waiting for us to Re-queue
What you need to care when designing a System that relies on Message Queue?
If you are going to apply the Message Queue pattern into your system, here are something you need to care about. They are from my experience and mistakes that we made over the last 5 years
- It is not the one solution for all the problems. Don’t use it to solve simple problem. If you
system is small, if the logic is simple, do NOT use it. Only think of it in term of scalability.
- Similarly for Microservices design, do NOT think of it when you start your project. (Read more at The downsides of Microservices)
- Do NOT split the flow into too small workers. This will just create a lot more overhead and more
problems for you to solve. Again, start with a simple worker that does good job, only split into
different workers when necessary.
- Again, this is similar to the mistake that many people make when they start applying Microservice design.
- You should design it with Failure in mind. One of the main advantage Message Queue is that it helps ensure the success of the message even in case of failure. In a high-scalable system, everything can fail, from the database, network to the third party services, or even the hardware itself. Designing for failure means that your message must be retry-able and produce correct result no matter how many times you run it and when you run it.
- Eventual consistency is also a concern. Retry-able also means that your data may be inconsistent at some of point of time (in case of error) but if you design it correctly, the data will eventually be consistent. You need to be prepared for this. The simplest technique is just to track the progress somewhere and display the progress for the user so they know that the data is still being processed.
- Because of Eventual consistency, you should use a good database to reduce the difficulty. Try to apply a database system that satisfies ACID and stay away from the ones that don’t (i.e those NoSQL databases). We used to have this pain.
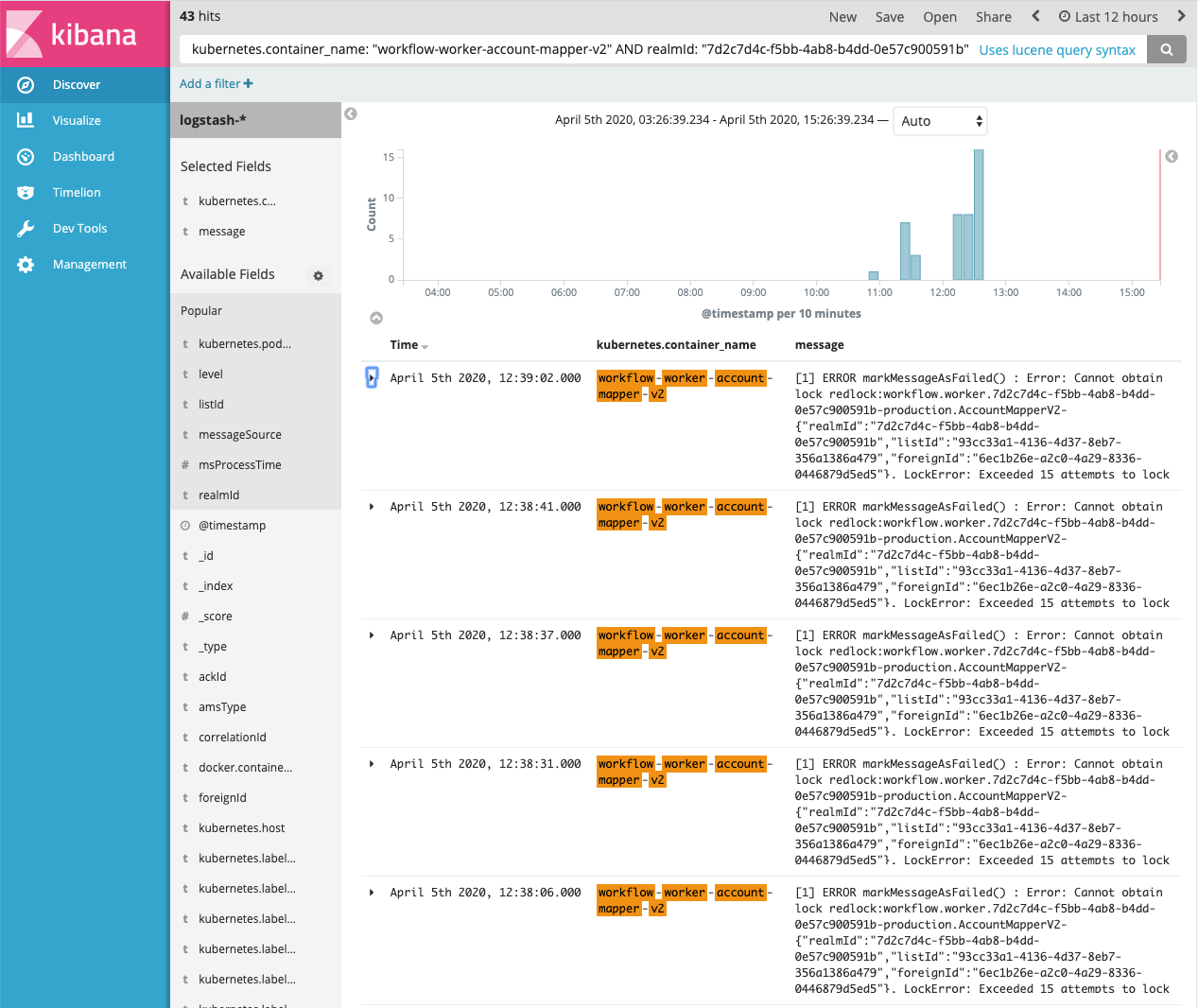
- You will soon end up with creating several different workers. Before starting the second one, you need to step back and define your standard for the Core library to create a new worker and for logging and debugging. Otherwise, you will soon get lost in all those async flows. For us, we had to apply a standard logging for all the workers written in all different languages by organizing all the log entries in ElasticSearch and use Kibana to search for the log entries that we want
Feel interested?
Drop me an email at [email protected] if you want to discuss or at [email protected] if you are looking for a hiring plan at AR