Let’s talk about Microservices again!
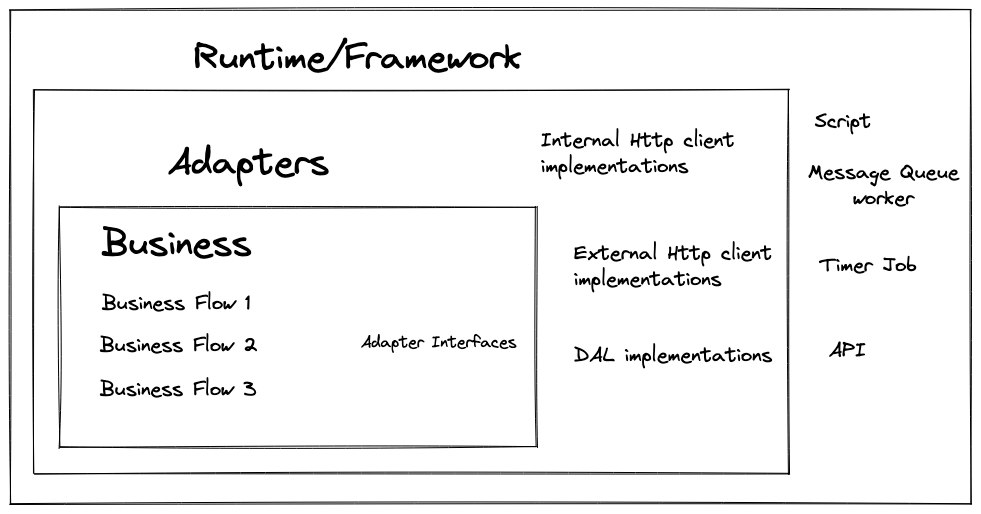
In order to manage a Microservices system efficiently, people usually enforce all the
microservices to
follow some common patterns. This helps you standardize the monitoring process and add a new
microservice more easily. In the Microservices project that I’m currently working on (at Agency
Revolution), we also have to
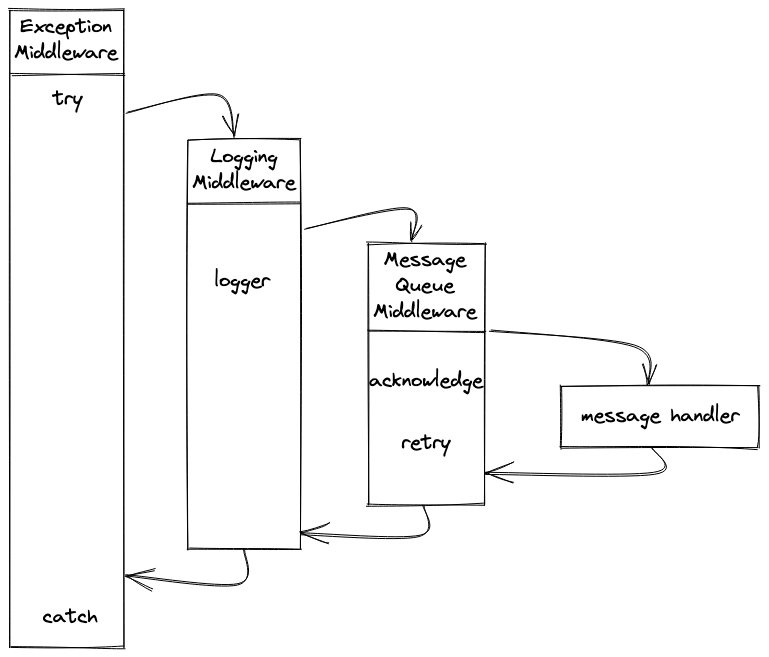
implement a base class for the each different type of microservice. The base
class contains the logic to write log in the correct format, to handle some common errors
correctly or to alert the developers if something go wrong, etc.
Basically, there are 2 types of Microservices in
our system: Synchronous and Asynchronous. I will focus mostly on one type of Async worker in
this post: The Message Queue workers.
The base class was initially built in Nodejs. After several years of development, we started to face
many problems with the design. And now, I’m going to show you how I identified the drawbacks and
improved it with a better version in C#.
Why C#? I may explain in another post. But right now, you
can take a look at this
post
first.
How it all began
First, we started with this Inheritance model, the way that most people will think of when they
start implementing a Worker base module. We defined a super class that all the workers in the system
can derive from. It
contains the logic to pull messages from the corresponding queue and
activate the main handler function.
// This is Javascript code
// The base class
class WorkerBase {
constructor(config) { this.queueName = config.queueName; }
async start() {
let message;
do {
message = await pullMessages(1); // pull 1 message at a time
await this.processMessage(message);
} while (message != null);
}
// implement this in the derived class
async processMessage(message) { throw new Error('Not implemented'); }
}
// Worker service 1
class Worker1 extends WorkerBase {
constructor() { super({ queueName: 'Worker1' }); }
async processMessage(message) {
// implement worker1 logic here
}
}
// Worker service 1
class Worker2 extends WorkerBase {
constructor() { super({ queueName: 'Worker2' }); }
async processMessage(message) {
// implement worker2 logic here
}
}
// to activate a worker
const worker = new Worker1();
await worker.start();