Nodejs has been a pain point in our code base for years. It used to be the best choice when we started building our product but I have never considered it as a good solution for scaling. I have been trying to find a better language and a better architecture which can help the team scale more in the future. I finally decided to go with C# and Clean Architecture. They are not the best one, but at least they fit for the existing tech stack of the organization.
I will have another series talking about the mistakes in designing application from my experience (which is also related the Nodejs code base). In this post, I’m going to summarize how I built the new architecture using Clean Architecture with C# and the advantages of MediatR to make it really clean.
Clean Architecture revisit
You may have already seen the famous Clean Architecture circle diagram many times before. It’s a bit complicated for me so I will make it simple by just drawing these 3 circles.
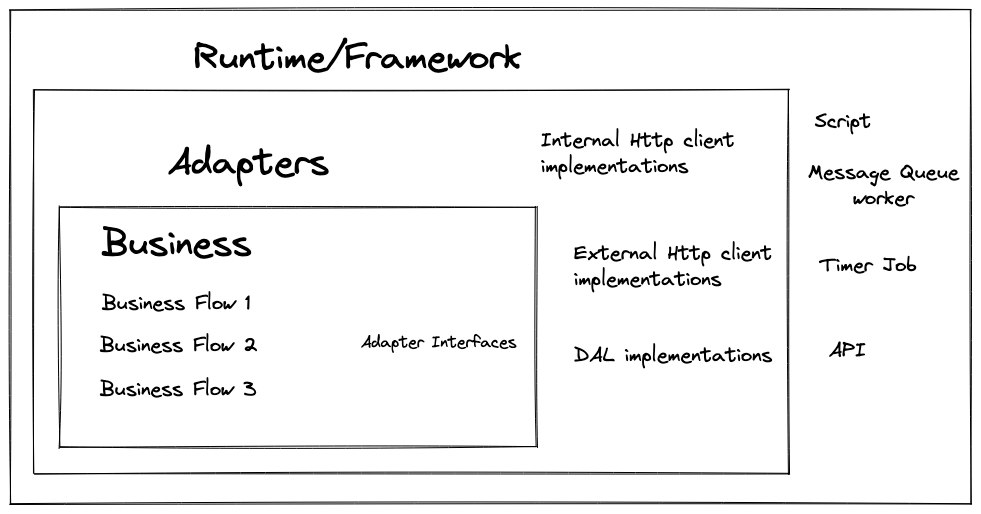
Each circle is represented by a Project in C#. The outer one references to the inner one, not the reverse way. The inner one should have no realization of the outer framework that it runs on top.
Fact: Naming is hard. I don’t really know if the above names are correct. They are not even the ones that I used in my code 😂. Well, names are just names, as long as we understand what they do, that’s enough.
Fact: You may have more than 3 layers (any number of layers that you want). I will keep it simple here.
Let’s go into the details of each one
1. Business Layer
The Design
This layer contains all the Core Business Flows of the application. They are pure C# code,
independent from the framework, database or any other external services. It doesn’t care if the
caller comes from an Http API, a Timer Worker or a Script. It also doesn’t know if it should read
the data from Redis, SQL Server or even from other external services. That means you should not see
such Attributes like Table or JsonPropertyName,…
All of those external
dependencies are expressed via a set of interfaces (with no implementation) that I called Adapter
interfaces.
Here are some benefits that you have using this layer
- You can easily write unit tests for your Core Business Flow without having to start all the
underlying infrastructure. Everything is in pure C# so it’s very fast to run. You are expected to
write most of your test suites here
- It is not tight coupling to the underlying infrastructure. You can easily swap the implementation for different environments as long as it satisfies the interface. For example, for accessing persistent data, you can choose an implementation with cache support to run on Production and another one to run for local development. It is also straight forward in case you want to change the data storage (migrate to a new database). For instance, the first version of the application sends requests to an external services to get the required data. Later one, you have all the data stored in your SQL server, simply switch to another implementation to read directly from your local database.
- Different teams/developers can work at the same time. One guy can take care of the business logic without having to wait for the data storage to be ready. There will be another guy responsible for implementing all the SQL-related feature and then integrate them together later.
The Code base
Here is how the code looks like. It’s just a Class Library with nearly no Nuget package installed
(of course except for some utility ones like AutoMapper or Autofac).
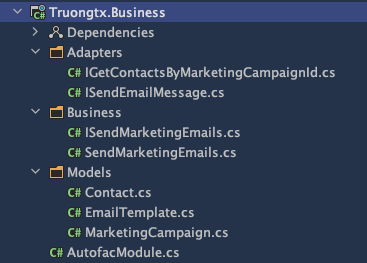
- Business: The core Business logic resides at the hear of the project.
- Models: Some necessary models for your application. They are POCO classes, no json or SQL attributes.
- Adapters: They are just interfaces to interact with the underlying infrastructure, for example, to download data from an external source, to query data from a SQL database,…
- And an AutofacModule file (because I use Autofac) to register the implementations for the Business interfaces.
(Of course, they are just for demonstration purpose. The real one looks much more complicated).
The application logic will assumes that the runtime has already supplied the necessary services
public interface ISendMarketingEmails
{
/// <summary>
/// Start sending Marketing Emails for the input Marketing Campaign
/// </summary>
/// <param name="marketingCampaignId"></param>
/// <returns></returns>
Task Execute(int marketingCampaignId);
}
public class SendMarketingEmails : ISendMarketingEmails
{
private readonly IGetContactsByMarketingCampaignId _getContacts;
private readonly ISendEmailMessage _sendEmail;
public SendMarketingEmails(IGetContactsByMarketingCampaignId getContacts, ISendEmailMessage sendEmail)
{
_getContacts = getContacts;
_sendEmail = sendEmail;
}
public async Task Execute(int marketingCampaignId)
{
// get list of contacts to send
var contacts = await _getContacts.Execute(marketingCampaignId);
// validate contacts
contacts = contacts.Where(
// some validation logic here
c => true
).ToList();
// get email template
var template = new EmailTemplate(); // replace your logic here
var emailContent = "my-content";
// send email
await Task.WhenAll(contacts.Select(contact => _sendEmail.Execute(template, contact.Email, emailContent)));
}
}
Testing is also straight forward. Usually you just need to mock the dependencies, or sometimes just send the object directly into the constructor.
public class SendMarketingEmailTest
{
public async Task MainFlowTest()
{
// prepare
var mock = AutoMock.GetLoose();
var getContacts = mock.Mock<IGetContactsByMarketingCampaignId>();
getContacts.Setup(...);
var sendEmail = mock.Mock<ISendEmailMessage>();
sendEmail.Setup...();
// act
var campaignId = 1;
var sendMarketingEmails = new SendMarketingEmails(getContacts.Object, sendEmail.Object);
await sendMarketingEmails.Execute(campaignId);
// assert
getContacts.Verify(...);
}
}