Part 4 Scaling the System at AR - Part 4 - Message Queue at AR
The problem of scaling team
As the product grows bigger and bigger, one team is not capable for developing and maintaining the whole system anymore. The organization won’t scale if we operate using a top-down style, where one Production Owner or Tech Leader dictates the decision of all teams. Sooner or later it will come a big monolith application, where the changes from one place can cause cascading effect to all the other teams.
The philosophy that we use for scaling the product is to split it into smaller ones, building multiple autonomous teams, each team is responsible for one (or more) business domain. Each individual team is free to experiment new technology and choose the tech stack that is most suitable for them without impacting the other teams.
There are, of course, plenty of difficulties when splitting team
- How to make those teams operate independently?
- How can we make sure the error in one team doesn’t cause cascading effect to the other team?
- How does one team access the data that another team manages?
- How does one team update the data that belongs to another team?
- How can one team encapsulate the underlying business logic from the other teams?
- How do we maintain the consistency across teams?
- What will happen if we add one (or more team) in the future?
- …
I won’t talk much about the process, operating or management skill here, just because I’m not an expert on that. I will just show some technical techniques related to Message Queue that we used to support the ultimate goal of splitting and building small autonomous teams.
How about an API Server for each team?
One simple way that people usually think of is to expose an API Server/Gateway to the other teams in the company. An API Server can help
- Limit the permission of other teams/services on the current team resources, allow the other teams to read/write certain entities only.
- Prevent the other teams to cause unwanted effect on the internal data structure of the current team.
- Abstract away the complex underlying business logic of the team.
- Each team can choose its own technology stack, no matter if they follow a Monolith or Microservice design, no matter if they use Nodejs or C#, as long as the API is a standard one (usually HTTP API).

However, this design also comes with many problems, more than the benefits that it as
- It has the advantages as well as the limitations of the Synchronous design
- What happens if the API Server (or one of the internal component of the team) is down? All the other teams consuming that API will be blocked. It prevents each individual team from operating independently.
- What happens if there is an error in the API Server logic? All the other teams rely on the data returned from the API will be affected. Again, teams are not autonomous anymore.
- In case of querying data, how does one team know which team owns the source data?
- In case of updating data, how does one team know which team consumes the data to update?
- Even if we know which team to update, what API should we call? For example, if there is a new entity created in our team, what are the related entities in other teams that we have to update? And why do we have to care?
- If we add one (or more) new team in the future, we will have to update code in all teams to make sure they update all the other data source when there are any changes.
Moving to an Asynchronous design
Since the above API design has several problems, we changed to a different architecture, based on the Message Queue features that Google Cloud provides, utilizing our existing infrastructure, for the purpose of building autonomous teams.
Here is a brief description of this Asynchronous design
- Each team should has its own database, independent from other teams.
- Each team should store its own data, duplicate the data from the other teams if necessary (no matter which team owns that data domain), but store just the properties required for that team, not everything related to that entity.
- The data will eventually be consistent across the system via a global Event (or Pub/Sub) system,
where one Publisher can notify the event to all the registered Subscribers. In case you
use Google Pub/Sub:
- Each event is represented by a Topic in Google Pub/Sub
- Each Subscription is actually a Message Queue.
- An event sent to a Topic will be distributed to all the Subscriptions it has, that means the same message will be duplicated to all the Subscribers’ queues.
- The same configuration can be achieved on AWS using SQS and SNS or Event Bridge
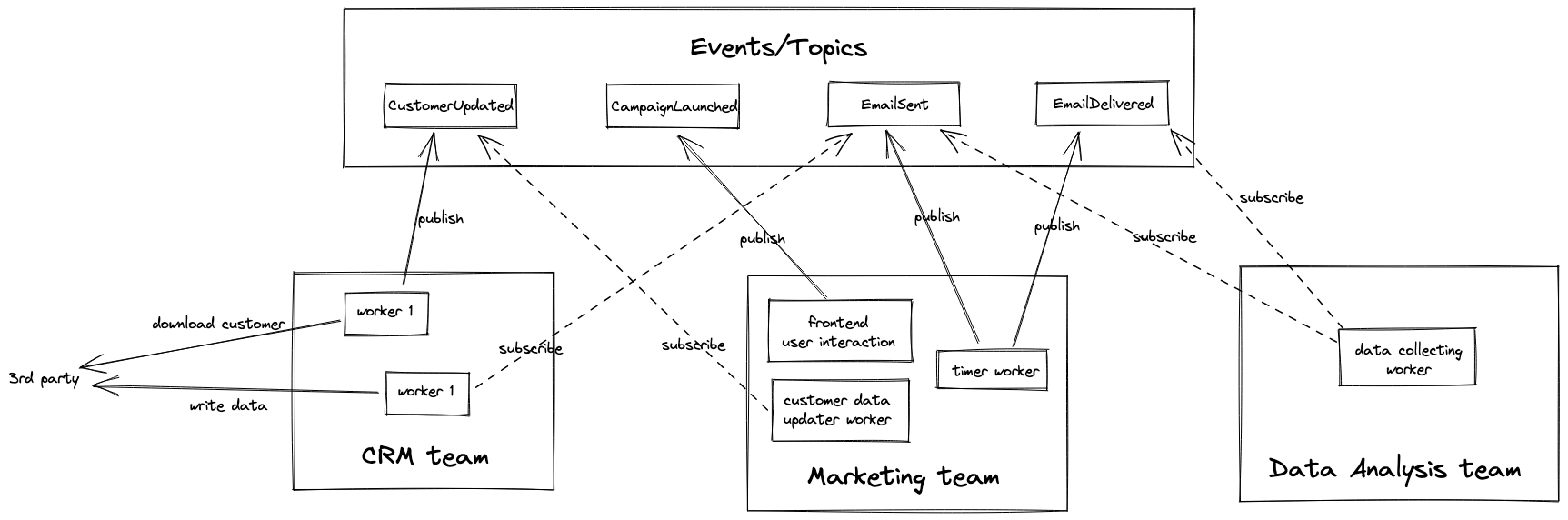
Let’s take a look at a simple flow for syncing Customer and Campaign data across teams in the above picture. Imagine that your organization has 3 different teams, CRM, Marketing and Data Analysis team. The CRM team provides the tool for your users to manage their Customer records. The Marketing team helps the users to configure and launch automated marketing Campaigns. The Data Analysis team collects data and give detailed reports back to your users.
The Customer objects originated from the CRM team database. If there are any changes to the Customer
data, the CRM team will publish a corresponding event (CUSTOMER_CREATED, CUSTOMER_UPDATED,
CUSTOMER_DELETE,…)
{
"topic": "CUSTOMER_CREATED",
"data": {
"customer": {
// ...
}
}
}
{
"topic": "CUSTOMER_DELETED",
"data": {
"customerId": "customer-id-1"
}
}
The Customer data is required to trigger Marketing Campaign. The Marketing team will subscribe to those events via Subscription. As mentioned before, a Subscription is actually a Message Queue. A worker in the Marketing team is responsible for consuming those messages and update the team’s database based on the message value.
Every time an Email is sent out from an Automated Marketing Campaign, the Marketing team will
send an event to the topic EMAIL_SENT. The message will be duplicated into 2 queues
(Subscriptions) for CRM team and Data Analysis to do their job.
Here are some benefits of this solution
- Most of the advantages of the above API design.
- Each team has its own data storage and can operate independently from other teams. The team is free to choose any technology, database and programming language that is best suited for that team.
- The system design will move toward the Microservice architecture. A failure in one team will only cause the system to be partially down. Your application can continue to function and deliver customer value.
- The team that generates an event doesn’t need to care about who will consume the event. This helps reduce the external dependencies on the team, cut down the cross-cutting concerns that one team need to handle.
- When you add another team, no changes need to be made to all the existing teams, simply add a new Subscription to any Topic to get the updates about the entity.
Of course, there is no such thing as a free lunch. It also comes with all the drawbacks of a common Message Queue system Read more…